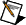
Regular expressions require specific combinations of characters for pattern matching. Use regular expressions to match or locate a portion or subset of a string. For example, you can use regular expressions to match a variable in a string of code or a specific value in a report.
|
Note The Match Regular Expression and Search and Replace String functions do not support null characters in strings. Also, a regular expression can return a successful match of an empty string. If a regular expression does not return a successful match, the offset past match will return –1. |
Regular expression support is provided by the PCRE library package. Refer to the <National Instruments>\_Legal Information directory for more information about the license under which the PCRE library package is redistributed.
Refer to the Perl 5 Regular Expression documentation at www.pcre.org for more information about Perl Compatible Regular Expressions.
Use the special characters in the following table in the regular expression input of the Match Regular Expression function and the search string input of the Search and Replace String function. To use special characters with the Search and Replace String function, right-click the function and select Regular Expression from the shortcut menu.
|
Note The following special characters are compatible only with the Match Regular Expression and Search and Replace String functions. The Match Pattern function uses a more limited set of regular expressions but performs more quickly than the Match Regular Expression function. Refer to the Special Characters for Match Pattern topic for more information about regular expressions for the Match Pattern function. |
| Special Character | Description | Example(s) |
|---|---|---|
| . (period) |
Matches any single character except a newline character. Within square brackets, . is literal. | Input String: Welcome to LabVIEW. Regular Expression: t.... Match: to La If you input [z.] as the regular expression, the period is literal and the expression matches either . or z. In this example, [z.] returns . as the match. |
| * | Marks the single preceding character, character group, or character class as one that can appear zero or more times in the input. Because an asterisk can match a pattern that appears zero times, regular expressions that include an asterisk can return an empty string if the whole pattern is marked with an asterisk. This quantifier matches as many characters as possible by default. | Input String: Hello LabVIEW! Regular Expression: el* Match: ell Expressions such as w* or (welcome)* match an empty string if the function finds no other matches. |
| + | Marks the single preceding character, character group, or character class as one that can appear one or more times in the input. This quantifier matches as many characters as possible by default. | Input String: Hello LabVIEW! Regular Expression: el+ Match: ell |
| ? | Marks the single preceding character, character group, or character class as one that can appear zero or one time in the input. This quantifier matches as many characters as possible by default.
When used immediately after a quantifier, ? modifies the quantifier to match as few times as possible. Modifiable quantifiers include *, +, and {}. |
Input String: Hello LabVIEW! Regular Expression: el? Match: el Input String: <ul><li>Hello</li><li>LabVIEW</li></ul> Regular Expression: <li>.+?</li> Match: <li>Hello</li> In the second example, if you remove ? from the regular expression, the new match becomes <li>Hello</li><li>LabVIEW</li> because + matches as many characters as possible unless you include ? immediately after +. You can use this regular expression to match any string within <li></li> tags. |
| {n,N} | Marks the single preceding character, character group, or character class as one that can appear the number of times you specify, where n is the minimum and N is the maximum. You also can specify a single number. If you specify a range, this quantifier matches as many times as possible. | Input String: <ul><li>Hello</li><li>Lab</li><li>VIEW</li><li>!</li></ul> Regular Expression: (<li>.+?</li>){2} Match: <li>Hello</li><li>Lab</li> Input String: <ul><li>Hello</li><li>Lab</li><li>VIEW</li><li>!</li></ul> Regular Expression: (<li>.+?</li>){1,3} Match: <li>Hello</li><li>Lab</li><li>VIEW</li> In the second example, the minimum match limit is one and the maximum is three. Because the regular expression matches as many times as possible within the limit you specify, the regular expression returns three matches. |
| [] | Creates a character class, which allows you to match any one of a set of characters that you specify. For example, [abc] matches a, b, or c.
You can use - to specify a range of characters. For example, [a-z] matches any single lowercase letter. The Match Regular Expression and Search and Replace String functions interpret special characters inside square brackets literally, with the exception of ^, -, and \. |
Input String: version=14.0.1 Regular Expression: [0-9]+(\.[0-9]+)* Match: 14.0.1 The expression [0-9] matches any digit. The plus sign matches the previous character class, [0-9], one or more times but as many times as possible. The parentheses create a character group, which creates a submatch of the . character and all following digits. The expression \. matches a literal . character. The plus sign matches the previous character class, [0-9], one or more times but matches as many times as possible. The asterisk matches the previous character group, (\.[0-9]+), zero or more times, so the regular expression still matches integers if there is no . character. You can use this regular expression to match any integer, decimal number, version number, IPv4 address, or other number sequence separated by . characters. |
| ( ) | Creates a character group, which allows you to match an entire set of characters that you specify. A quantifier that immediately follows a character group quantifies the entire group.
Parentheses also create submatches where each individual character group returns a submatch. If you nest a character group within another character group, the regular expression creates a submatch for the outer group before the inner group. Expand the Match Regular Expression function node to access submatch outputs. You also can refer back to submatches later in an expression using backreferences. Refer to the Backreferences section below for more information about using backreferences in regular expressions. |
Input String: Hello LabVIEW! Regular Expression: (el.)..(L..) Match: ello Lab Submatch 1: ell Submatch 2: Lab Input String: Hello LabVIEW! Regular Expression: (.(el.).).(L..) Match: Hello Lab Submatch 1: Hello Submatch 2: ell Submatch 3: Lab |
| | | Separates alternate possible matches. This character is useful when you want to match any of a number of character groups. A regular expression that contains (|) returns the first match that the function finds in the input string regardless of the order of your possible matches. For example, both regular expressions dog|cat and cat|dog match dog in the dog chased the cat. | Input String: value=FALSE total=12.34 token=TRUE Regular Expression: (value|token)=(TRUE|FALSE) Match: value=FALSE Submatch 1: value Submatch 2: FALSE The regular expression returns the first possible match in the input string. If token=TRUE appeared before value=FALSE in the input string, the regular expression would match token=TRUE instead. |
| ^ | Anchors a match to the beginning of a string when used as the first character of a pattern.
If you set the multiline? input to TRUE on the Match Regular Expression or Search and Replace String functions, ^ matches the beginning of any line within the string using the line endings of the current platform. You also can match any character not in a given character class by adding ^ to the beginning of a character class. For example, [^0-9] matches any character that is not a digit. [^a-zA-Z0-9] matches any character that is not a lowercase or uppercase letter and also not a digit. |
Input String: Hello LabVIEW! Regular Expression: ^[^ ]+ Match: Hello The regular expression matches as many characters as possible—other than a space character—from the beginning of the input string. You can use this regular expression to isolate the first word, numeral, or other character combination of a string. Input String: Hello LabVIEW Regular Expression: ^LabVIEW Match: LabVIEW The regular expression matches LabVIEW only if you set multiline? to TRUE. |
| $ | Anchors a match at the end of a string when used as the last character of a pattern.
If you set the multiline? input to TRUE on the Match Regular Expression or Search and Replace String functions, $ matches the end of any line within the string using the line endings of the current platform. |
Input String: Hello LabVIEW! Regular Expression: [^ ]+$ Match: LabVIEW! The regular expression matches as many characters as possible—other than a space character—from the end of the input string. You can use this regular expression to isolate the last word, numeral, or other character combination of a string. Input String: Hello LabVIEW Regular Expression: Hello$ Match: Hello The regular expression matches Hello only if you set multiline? to TRUE. |
| \ | Cancels the special meaning of any special character in this list that immediately follows the backslash and instead matches the literal character. The following escaped expressions have special meanings:
|
Input String: total=$12.34 Regular Expression: \$\d+(\.\d{2})? Match: $12.34 The expression \$ matches a literal dollar sign because the backslash cancels the special meaning. The expression \d+ matches as many digits as possible and must match at least one digit. The expression (\.\d{2})? matches . and two digits, but ? makes this portion of the regular expression optional to match. You can use this regular expression to match dollar values that use a . character as a decimal separator. Locales that use a different character as a decimal separator must adapt the regular expression. Input String: NEWtoken=FALSE token=TRUE checkFile=TRUE total=12.34 Regular Expression: \btoken=\w+\s\b\S* Match: token=TRUE checkFile=TRUE The regular expression does not match token=FALSE in NEWtoken=FALSE because \b makes the regular expression match token= only at the beginning of a word. The expression \w+ matches as many word characters as possible and must match at least one. In this example, \w+ matches TRUE. The expression \s matches a space character. The expression \b\S* matches all non-white space characters that begin a word until the function finds another white space character. In this example, \b\S* matches checkFile=TRUE. Input String: Welcome to LabVIEW! Regular Expression: come\n\S*\t\w*\x21 Match: come to LabVIEW! The expression come\n matches the literal letters followed by a newline character. The expression \S* matches as many non-white space characters as possible, which is the word to in this case. The expression \t matches the tab in between to and LabVIEW!. The expression \w* matches as many word characters as possible, which is LabVIEW in this case. The expression \x21 matches the exclamation point because 21 is the hexadecimal code for an exclamation point. |
 |
Tip To anchor a match at the beginning and end of a string, use ^ as the first character in a pattern and $ as the last character of a pattern. For example, ^LabVIEW$ matches LabVIEW in LabVIEW but not in LabVIEW! or Hello LabVIEW. Anchoring the match at the beginning and end of the string requires the whole string to match. |
Use the following special characters in the replace string input of the Search and Replace String function.
| Special Character | Description | Example(s) |
|---|---|---|
| $n or ${n} | Inserts a string you specify before or after the submatch you specify. Refer to the Backreferences section below for more information about using backreferences in the replace string input of the Search and Replace String function.
Use ${n} if you have more than nine submatches in a regular expression and want to refer to a submatch after the ninth. $12 inserts only the first submatch because the function reads only the first digit that immediately follows $. However, ${12} inserts the twelfth submatch. |
input string: Welcome LabVIEW search string: (LabVIEW) replace string: to $1! result string: Welcome to LabVIEW! input string: Welcome to the LabVIEW Help! search string: We(l)(co(m)e)( )(to)( )t(he) (Lab)(VIE(W)) He(lp)(!) replace string: $7${11}ful${12} result string: helpful! |
| \$n | Cancels the interpretation of any special character you use in the replace string. | input string: total=123 per day search string: (\d+)(per \w*)? replace string: \$$1$2 result string: total=$123 per day As in this example, use \$ to insert the literal character $. Use \\ to indicate a literal backslash. |
Use backreferences to refer to previous submatches within the same regular expression. You can use backreferences to create a submatch using a character group in one part of an expression and then match that exact submatch in a later part of the expression.
To specify a back reference in the regular expression input of the Match Regular Expression function or the search string input of the Search and Replace String function, use \1 to refer to the first submatch, \2 to refer to the second, and so on. For example, consider the following regular expression:
(["*$])(\w+)\1\2\1
The first character group contains a character class that matches ", *, or $. The second character group matches one or more word characters. The first backreference, \1, matches the same submatch as the first character group, (["*$]). The second backreference, \2, matches the same submatch as the second character group, (\w+). The third backreference, \1, is identical to the first backreference and matches the same submatch as the first character group.
This example matches strings such as "foo"foo", *bar*bar*, and $baz$baz$, but does not match strings such as "foo$foo" or "foo*bar".
When you use the Search and Replace String function in Regular Expression mode, you can specify a backreference in the replace string input that refers to submatches in the search string input. Use $1 to refer to the first submatch, $2 to refer to the second submatch, and so on. You can use these special characters only in the replace string input of the Search and Replace String function. Use these special characters to insert a string you specify before or after the submatch you specify. Consider the following example:
input string: $value "TRUE"TRUE" *NULL
search string: (["*$])(\w+)\1\2\1
replace string: $1$2value$1
result string: $value "TRUEvalue" *NULL
In this example, the $1 backreferences in replace string refer to the first submatch in search string. Likewise, the $2 backreference refers to the second submatch in search string.
Match Regular Expression Function
Search and Replace String Function