|
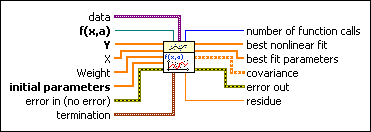
data specifies static data that the user-defined function needs at run time.
|
 |
f(x,a) is a reference to the VI that implements the fitting model. a is the set of parameters LabVIEW calculates. Use the VI template located at labview\vi.lib\gmath\NumericalOptimization\LM model function and gradient.vit to create the VI from a template.
 Open template Open template
|
 |
Y specifies the array of dependent values, or the observations. The number of input points must be greater than zero.
|
|
X specifies the array of independent values. The number of input points must be greater than zero.
|
|
Weight is the array of weights for the observations Y. If Weight is unwired, this VI sets all elements of Weight to 1. If Weight has fewer elements than Y, this VI pads the end of Weight with ones so that the length of Weight equals the length of Y. If Weight has more elements than Y, this VI ignores the extra elements at the end of Weight. If an element in Weight is less than 0, this VI uses the absolute value of the element.
|
|
initial parameters specifies the initial guess for best fit parameters. The length of initial parameters must equal the length of a in f(x,a). The success of the nonlinear curve fit depends on how close the initial parameters are to the best fit parameters. Therefore, use any available resources to obtain good initial guess parameters to the solution before you use this VI.
|
 |
error in describes error conditions that occur before this node runs. This input provides standard error in functionality.
|
 |
termination specifies the stopping conditions for the fitting process.
 |
max iteration specifies the largest number of iterations of the fitting routine. If the number of iterations exceeds max iterations, the fitting process terminates.
|
 |
tolerance specifies the relative change in the weighted distance between Y and the current fit. If the relative change falls below tolerance, the fitting process terminates.
|
|
 |
number of function calls returns the number of times LabVIEW called f(x,a) during the fitting process.
|
 |
best nonlinear fit returns the y-values of the fitted model that correspond to the independent values in X.
|
|
best fit parameters returns the array of parameters that minimizes the weighted mean square error between the best nonlinear fit and the observations in Y.
|
 |
covariance returns the matrix of covariances. Cjk is the covariance between a[j] and a[k]. c[jj] is the variance of a[j]. This VI generates the covariance, C, according to the following equation:
C = (0.5D)^–1
where D is the Hessian of the function with respect to its parameters.
|
 |
error out contains error information. This output provides standard error out functionality.
|
 |
residue returns the weighted mean square error between the best nonlinear fit and Y.
|
|
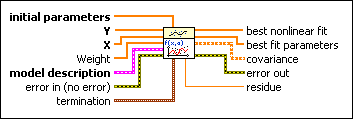
initial parameters specifies the initial guess for best fit parameters. The length of initial parameters must equal the length of Parameters in model description. The success of the nonlinear curve fit depends on how close the initial parameters are to the best fit parameters. Therefore, use any available resources to obtain good initial guess parameters to the solution before you use this VI.
|
|
Y specifies the array of dependent values, or the observations. The number of input points must be greater than zero.
|
|
X specifies the array of independent values. The number of input points must be greater than zero.
|
|
Weight is the array of weights for the observations Y. If Weight is unwired, this VI sets all elements of Weight to 1. If Weight has fewer elements than Y, this VI pads the end of Weight with ones so that the length of Weight equals the length of Y. If Weight has more elements than Y, this VI ignores the extra elements at the end of Weight. If an element in Weight is less than 0, this VI uses the absolute value of the element.
|
 |
model description specifies the formula string description of the model to which you want to apply a nonlinear curve fit. Where the Formula Nodes and the parser in the Mathematics VIs differ, this VI uses the parser syntax. For example, for exponentiation, use the parser syntax ^ rather than the Formula Node syntax **.
|
|
error in describes error conditions that occur before this node runs. This input provides standard error in functionality.
|
|
termination specifies the stopping conditions for the fitting process.
|
max iteration specifies the largest number of iterations of the fitting routine. If the number of iterations exceeds max iterations, the fitting process terminates.
|
|
tolerance specifies the relative change in the weighted distance between Y and the current fit. If the relative change falls below tolerance, the fitting process terminates.
|
|
|
best nonlinear fit returns the y-values of the fitted model that correspond to the independent values in X.
|
|
best fit parameters returns the array of parameters that minimizes the weighted mean square error between the best nonlinear fit and the observations in Y.
|
|
covariance returns the matrix of covariances. Cjk is the covariance between a[j] and a[k]. c[jj] is the variance of a[j]. This VI generates the covariance, C, according to the following equation:
C = (0.5D)^–1
where D is the Hessian of the function with respect to its parameters.
|
|
error out contains error information. This output provides standard error out functionality.
|
|
residue returns the weighted mean square error between the best nonlinear fit and Y.
|
The Hessian matrix is a common matrix in numerical optimization methods, such as the Newton method. To avoid the weakness of the singular Hessian matrix, the Levenberg-Marquardt method adds a positive definite diagonal matrix to the Hessian matrix. This positive definite diagonal matrix is the main difference between the Levenberg-Marquardt method and the Gauss-Newton method. Refer to Numerical Optimization in the Mathematics Related Documentation topic for more information about the Levenberg-Marquardt method.
You can use the nonlinear Levenberg-Marquardt method to fit linear or nonlinear curves. However, when you fit a linear curve, the General Linear Fit VI is more efficient than this VI. You must verify the results you obtain with the Levenberg-Marquardt method because the method does not always guarantee a correct result.
 Add to the block diagram
Add to the block diagram Find on the palette
Find on the palette