 |
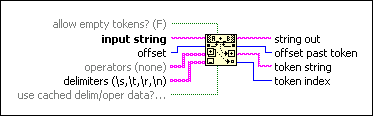
allow empty tokens? determines whether the function recognizes a token when it encounters multiple adjacent delimiters. If allow empty tokens? is FALSE (default), multiple adjacent delimiters can separate two tokens in input string. If allow empty tokens? is TRUE, an empty token string is returned between every pair of adjacent delimiters.
|
 |
input string is the string to scan for tokens.
|
 |
offset is the point in input string to begin scanning. The default is 0, which specifies the beginning of the string.
|
 |
operators is an array of strings that the function identifies as tokens when they appear in input string, even if they are not surrounded by delimiters. If a portion of input string matches more than one defined operator, the function chooses the longest match as a token. For example, if >, = and >= are defined operators, the input string 4>=0 produces >= as the next token string with an offset of 1.
A string in operators might contain the following special format codes, which you can use to scan entire numbers as single tokens.
| %d | match decimal integer |
| %o | match octal integer |
| %x | match hexadecimal integer |
| %b | match binary integer |
| %e,%f,%g | match floating-point or scientific real number |
| %% | match a single % character |
 | Note If the strings + or – are defined as operators, the function does not recognize leading, or unary, + and – signs. The function always returns them as separate tokens. This is an exception to the "longest match" rule. |
|
|
delimiters is an array of strings that act as separators between tokens. Strings in delimiters are not returned as tokens but serve to separate adjacent tokens from each other. The default delimiters are the white space characters: space, tab, linefeed, and carriage return.
|
|
use cached delim/oper data? is an advanced optional input. If unwired, token string still behaves correctly. However, you can use use cached delim/oper data? to greatly improve string parsing performance. Set use cached delim/oper data? to FALSE the first time token string is executed, and TRUE each subsequent time as long as operators and delimiters have not changed. Use a shift register with a constant FALSE coming in and a constant TRUE going out to ensure correct behavior if operators and delimiters do not change during the execution of the loop. If use cached delim/oper data? is TRUE and operators or delimiters has changed since the last execution, incorrect output might result. If both operators and delimiters are unwired or are wired to block diagram constants, you can leave use cached delim/oper data? unwired and still achieve optimal performance.
|
 |
string out returns input string unchanged.
|
 |
offset past token identifies the point in the input string immediately following the most recently found token and any trailing delimiters. Any subsequent scanning of the same input string should begin at this offset. If offset is less than 0 or greater than the number of characters in input string, or if the end of the string was reached, offset past token is –1.
|
|
token string is the matched token. It can be one of the strings in operators or any text string in input string that appears between delimiters.
|
|
token index is the index of token string in operators if token string matches one of the elements in operators. If token string is any other string, token index returns –1. If the function reaches the end of input string without finding any valid operator, token index returns –2.
|
Tokens are text segments that typically represent individual keywords, numeric values, or operators found when parsing a configuration file or other text-based data format. You can specify tokens with the data you pass into the function through the delimiters and operators inputs. For example, because the space character is a delimiter by default, each word of This is a string is a token, and you can parse the sentence into its component words.
By default, the function identifies and returns a token when it encounters a space, tab, carriage return, or linefeed. You can parse a string using these or any other delimiters you choose or you can define operators.
For example, suppose you wire the following values to the function.
If you place the function in a While Loop, the function returns the following values.
 Add to the block diagram
Add to the block diagram Find on the palette
Find on the palette