 |
X is the first input sequence.
|
|
Y is the second input sequence.
|
 |
algorithm specifies the convolution method to use. When algorithm is direct, this VI computes the convolution using the direct method of linear convolution. When algorithm is frequency domain, this VI computes the convolution using an FFT-based technique. If X and Y are small, the direct method typically is faster. If X and Y are large, the frequency domain method typically is faster. Additionally, slight numerical differences can exist between the two methods.
| 0 | direct | | 1 | frequency domain (default) |
|
 |
X * Y is the convolution of X and Y.
|
 |
error returns any error or warning from the VI. You can wire error to the Error Cluster From Error Code VI to convert the error code or warning into an error cluster.
|
 |
X is the first complex valued input sequence.
|
|
Y is the second complex valued input sequence.
|
|
algorithm specifies the convolution method to use. When algorithm is direct, this VI computes the convolution using the direct method of linear convolution. When algorithm is frequency domain, this VI computes the convolution using an FFT-based technique. If X and Y are small, the direct method typically is faster. If X and Y are large, the frequency domain method typically is faster. Additionally, slight numerical differences can exist between the two methods.
| 0 | direct | | 1 | frequency domain (default) |
|
 |
X * Y is the convolution of X and Y.
|
|
error returns any error or warning from the VI. You can wire error to the Error Cluster From Error Code VI to convert the error code or warning into an error cluster.
|
 |
X is the first input sequence.
|
|
Y is the second input sequence.
|
|
algorithm specifies the convolution method to use. When algorithm is direct, this VI computes the convolution using the direct method of linear convolution. When algorithm is frequency domain, this VI computes the convolution using an FFT-based technique. If X and Y are small, the direct method typically is faster. If X and Y are large, the frequency domain method typically is faster. Additionally, slight numerical differences can exist between the two methods.
| 0 | direct | | 1 | frequency domain (default) |
|
|
output size determines the size of X * Y.
| 0 | full (default)—Sets the width of X * Y to one less than the sum of the widths of X and Y and sets the height of X * Y to one less than the sum of the heights of X and Y. | | 1 | size X—Sets the width and height of X * Y to the width and height of X. | | 2 | compact—Sets the width of X * Y to one more than the difference of the widths of X and Y and sets the height of X * Y to one more than the difference of the heights of X and Y. The width and height of X must be greater than or equal to the width and height of Y, respectively, when output size is compact. |
|
 |
X * Y is the convolution of X and Y.
|
|
error returns any error or warning from the VI. You can wire error to the Error Cluster From Error Code VI to convert the error code or warning into an error cluster.
|
 |
X is the first complex valued input sequence.
|
|
Y is the second complex valued input sequence.
|
|
algorithm specifies the convolution method to use. When algorithm is direct, this VI computes the convolution using the direct method of linear convolution. When algorithm is frequency domain, this VI computes the convolution using an FFT-based technique. If X and Y are small, the direct method typically is faster. If X and Y are large, the frequency domain method typically is faster. Additionally, slight numerical differences can exist between the two methods.
| 0 | direct | | 1 | frequency domain (default) |
|
|
output size determines the size of X * Y.
| 0 | full (default)—Sets the width of X * Y to one less than the sum of the widths of X and Y and sets the height of X * Y to one less than the sum of the heights of X and Y. | | 1 | size X—Sets the width and height of X * Y to the width and height of X. | | 2 | compact—Sets the width of X * Y to one more than the difference of the widths of X and Y and sets the height of X * Y to one more than the difference of the heights of X and Y. The width and height of X must be greater than or equal to the width and height of Y, respectively, when output size is compact. |
|
 |
X * Y is the convolution of X and Y.
|
|
error returns any error or warning from the VI. You can wire error to the Error Cluster From Error Code VI to convert the error code or warning into an error cluster.
|
1D Convolution
The linear convolution of the signals x(t) and y(t) is defined as:
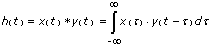
where the symbol * denotes linear convolution.
When algorithm is direct, this VI uses the following equation to perform the discrete implementation of the linear convolution and obtain the elements of X * Y.
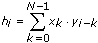
for i = 0, 1, 2, … , M+N–2
where h is X * Y
N is the number of elements in X,
M is the number of elements in Y,
the indexed elements outside the ranges of X and Y are equal to zero, as shown in the following relationships:
xj = 0, j < 0, or j  N
N
and
yj = 0, j < 0, or j M.
When algorithm is frequency domain, this VI completes the following steps, in order, to compute the linear convolution:
- First, this VI pads the end of X and Y with zeros to make their lengths M + N – 1, as shown in the following equations.
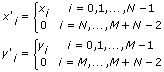
- Second, this VI calculates the Fourier transform of X' and Y' according to the following equations.
X'(f) = FFT(x')
Y'(f) = FFT(y')
- Third, this VI multiplies X'(f) by Y'(f) and calculates the inverse Fourier transform of the product. The result is the linear convolution of X and Y, as shown in the following equation.
X * Y = IFFT(X'(f) · Y'(f))
Thus, this VI computes the linear convolution, not the circular convolution. However, because x(t) * y(t)N  X(f)Y(f) is a Fourier transform pair, where x(t) * y(t)N is the circular convolution of x(t) and y(t), you can create a circular version of the convolution. To compute the circular convolution, you can use a block diagram similar to the block diagram shown in the following illustration.
X(f)Y(f) is a Fourier transform pair, where x(t) * y(t)N is the circular convolution of x(t) and y(t), you can create a circular version of the convolution. To compute the circular convolution, you can use a block diagram similar to the block diagram shown in the following illustration.
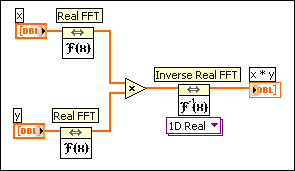
2D Convolution
When algorithm is direct, this VI uses the following equation to compute the two-dimensional convolution of the input matrices X and Y.
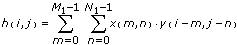
for i = 0, 1, 2, … , M1+M2–2 and j = 0, 1, 2, … , N1+N2–2
where h is X * Y,
M1 is the number of rows of matrix X,
N1 is the number of columns of matrix X,
M2 is the number of rows of matrix Y,
N2 is the number of columns of matrix Y,
The indexed elements outside the ranges of X and Y are equal to zero, as shown in the following relationships:
x(m,n), m < 0 or m M1 or n < 0 or n N1
and
y(m,n) , m < 0 or m M2 or n < 0 or n N2.
When algorithm is frequency domain, this VI completes the following steps, in order, to compute the two-dimensional convolution:
- First, this VI pads the end of X and Y with zeros to make their sizes (M1 + M2 – 1)-by-(N1 + N2 – 2), as shown in the following equations.
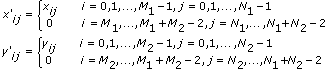
- Second, this VI calculates the Fourier transform of X' and Y' according to the following equations.
X'(f) = FFT(x')
Y'(f) = FFT(y')
- Third, this VI multiplies X'(f) by Y'(f) and calculates the inverse Fourier transform of the product. The result is the two-dimensional convolution of X and Y, as shown in the following equation.
X * Y = IFFT(X'(f) · Y'(f))
The output size determines the size of the output matrix X * Y as shown in the following illustration.
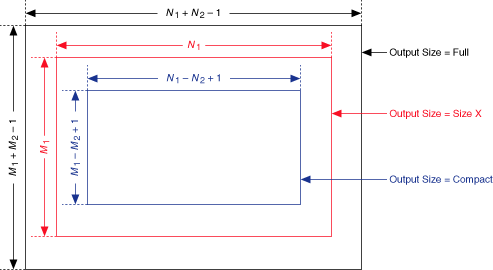
- full
The output matrix X * Y is (M1+M2–1)-by-(N1+N2–1).
- size X
This is useful in image processing. If X is the image you want to filter, Y is a small matrix called the convolution kernel. X * Y is the filtered image whose size is the same as that of image X. The output M1-by-N1 matrix is the central part of the output matrix when the output size is full.
- compact
Computing the edge elements of X * Y requires zero-padding if the output size is full or size X. LabVIEW removes these edge elements if the output size is compact. The output (M1–M2+1)-by-(N1–N2+1) matrix is the central part of the output matrix when the output size is size X.
Refer to the Edge Detection with 2D Convolution VI in the labview\examples\Signal Processing\Signal Operation directory for an example of using the Convolution VI.
 Open example
Open example  Find related examples
Find related examples
 Add to the block diagram
Add to the block diagram